在之前的文章中,我们学习了分类学习之支持向量机,并带来简单案例,学习用法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-机器学习(6)分类学习之支持向量机-CSDN博客文章浏览阅读1.5k次,点赞28次,收藏25次。今天的文章,我们来学习分类学习之支持向量机,并带来简单案例,学习用法。希望大家能有所收获。同时,希望我的文章能帮助到每一个正在学习的你们。也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/138260328今天的文章,我们来学习分类学习之决策树,并带来简单案例,学习用法。希望大家能有所收获。
目录
一、决策树
什么是决策树
spark决策树
二、示例代码
完整代码
方法解析
代码效果
代码输出
拓展-spark决策树
一、决策树
什么是决策树

决策树模型
决策树是一种基本的分类与回归方法。它主要被用于分类问题,但也可以用于回归问题。决策树模型呈树形结构,其中每个内部节点表示一个属性上的判断条件,每个分支代表一个判断条件的输出,每个叶节点代表一个类别。
决策树学习的目的是根据给定的训练数据集构建一个决策树模型,以便能够对新样本进行正确的分类。决策树学习通常包括三个步骤:特征选择、决策树的生成和决策树的剪枝。
- 特征选择:选择对训练数据具有分类能力的特征。特征选择的目的是决定用哪个特征来划分空间。常用的选择准则有信息增益、增益率和基尼指数。
- 决策树的生成:基于特征选择的结果,递归地构建决策树。从根节点开始,对每个特征进行测试,根据测试结果将样本分配到子节点,直到满足停止条件(例如,所有样本属于同一类,或没有剩余特征可用)为止。
- 决策树的剪枝:为了避免过拟合,通常需要对决策树进行剪枝。剪枝的主要目的是简化模型,提高模型的泛化能力。剪枝可以通过预剪枝(在决策树生成过程中进行剪枝)或后剪枝(在决策树生成完成后进行剪枝)来实现。
决策树具有直观、易于理解和实现的优点。然而,它也可能导致过拟合,特别是在处理具有复杂关系的数据集时。此外,决策树对输入数据的预处理(如缺失值和异常值的处理)和参数设置(如停止条件和剪枝策略)也比较敏感。
spark决策树
Spark决策树是Apache Spark MLlib库中提供的一种机器学习算法,用于分类和回归问题。Spark决策树基于传统的决策树算法,并结合了Spark的分布式计算能力,以处理大规模数据集。
Spark决策树在构建过程中,通过递归地将数据集分割成子集来创建树形结构。每个内部节点代表一个特征上的判断条件,根据该条件将数据集划分为不同的子集,并分配给子节点。这个过程一直进行到满足停止条件为止,例如所有样本属于同一类或者没有剩余特征可用。
Spark决策树支持多种特征选择准则,如信息增益、增益率和基尼指数,以便根据数据的特性选择最合适的划分策略。同时,为了防止过拟合,Spark决策树也提供了剪枝机制,可以在决策树生成过程中或生成完成后进行剪枝。
由于Spark的分布式计算能力,Spark决策树可以有效地处理大规模数据集,并且具有良好的扩展性。这使得它成为处理大规模机器学习问题的一种有效方法。
二、示例代码
下面的示例代码的主要作用是训练一个决策树分类模型 ,通过直接在程序中模拟数据来达到我们展示一个决策树的过程,仅作为学习阶段的示例。在工作中,数据往往庞大而复杂,需要我们花费更长的时间来处理数据和优化模型。
完整代码
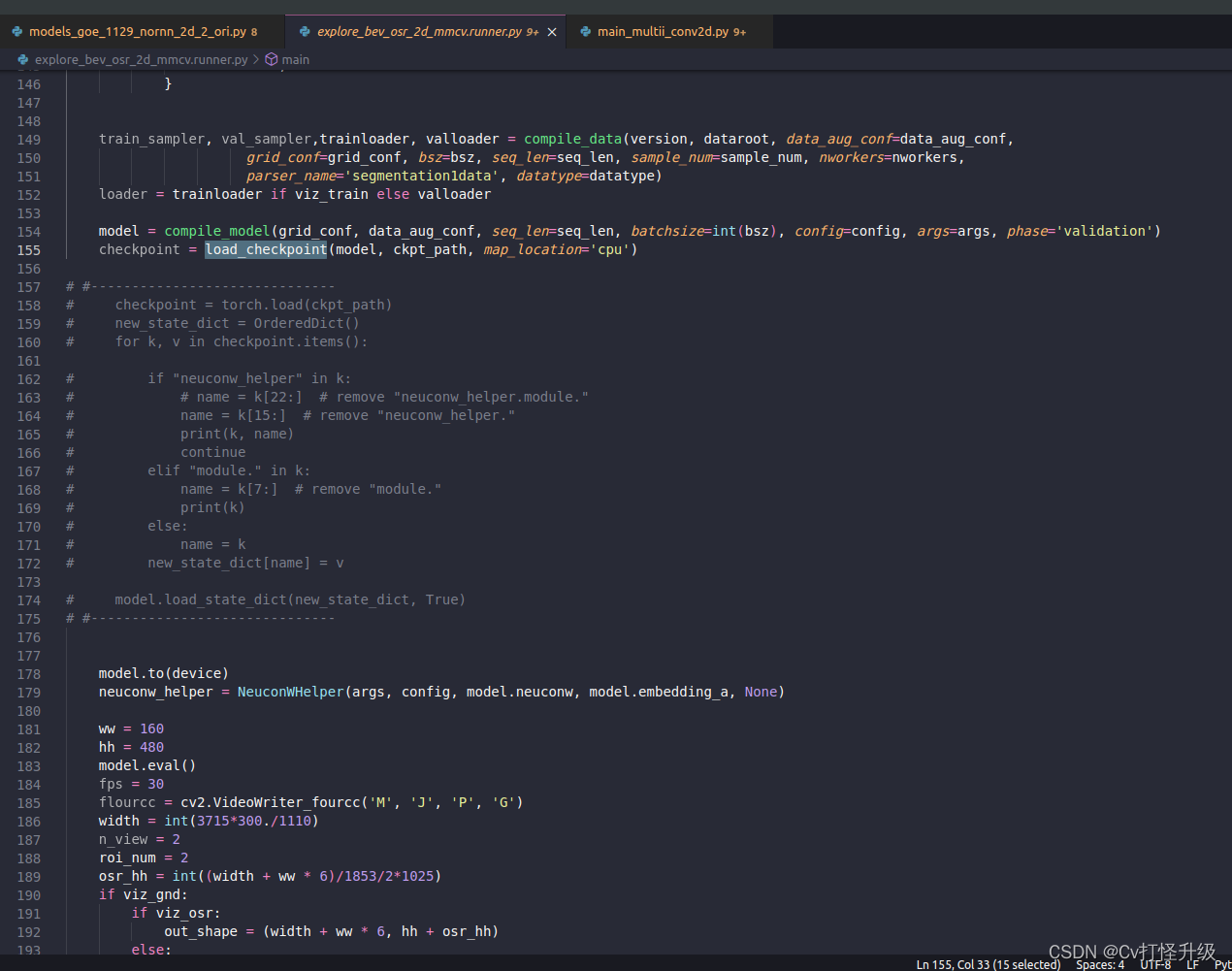
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler}
import org.apache.spark.sql.SparkSession
object p7{
def main(args: Array[String]): Unit = {
// 初始化Spark
val conf = new SparkConf().setAppName("Peng0426.").setMaster("local[*]")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().appName("SimpleDecisionTreeExample").getOrCreate()
import spark.implicits._
// 创建模拟数据
val data = Seq(
(1.0, 0.0, "A"), (1.5, 1.0, "A"), (5.0, 5.0, "B"), (5.0, 8.0, "B"), (1.0, 4.0, "A"), (1.5, 1.0, "A"), (5.5, 5.0, "B"), (8.0, 7.0, "B"), (1.0, 0.0, "A"), (2.5, 1.0, "A"), (5.5, 5.0, "B"), (8.0, 6.0, "B"),
).toDF("feature1", "feature2", "label")
// 将标签列从字符串类型转换为数值类型
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(data)
// 将特征列组合成一个特征向量
val assembler = new VectorAssembler()
.setInputCols(Array("feature1", "feature2"))
.setOutputCol("features")
// 创建决策树分类器
val dt = new DecisionTreeClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("features")
// 创建管道
val pipeline = new Pipeline()
.setStages(Array(labelIndexer, assembler, dt))
// 将数据划分为训练集和测试集
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
// 训练模型
val model = pipeline.fit(trainingData)
// 预测测试集
val predictions = model.transform(testData)
//计算测试误差
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test Accuracy = $accuracy")
}
}方法解析
-
SparkConf 和 SparkContext: 用于初始化Spark应用程序的配置和上下文。
-
SparkSession: 是Spark 2.0及以上版本中引入的新概念,用于替代SparkContext来创建DataFrame、Dataset和读取数据。
-
Pipeline: 在Spark ML中,Pipeline是一个用于组合多个转换步骤(如特征转换、模型训练等)的框架。
-
StringIndexer: 用于将字符串类型的标签列转换为数值类型,以便用于机器学习模型。
-
VectorAssembler: 将多个特征列组合成一个特征向量,这通常是机器学习模型所需要的输入格式。
-
DecisionTreeClassifier: 决策树分类器,用于训练决策树模型。
-
MulticlassClassificationEvaluator: 用于评估多分类模型性能的评估器。
-
DataFrame API: Spark的DataFrame API用于处理结构化数据。
代码效果
-
初始化Spark: 通过设置
SparkConf和SparkSession来初始化Spark应用程序。 -
创建模拟数据: 创建一个包含两个特征列和一个标签列的DataFrame。
-
数据预处理: 使用
StringIndexer和VectorAssembler进行数据预处理,将标签转换为数值类型,并将特征组合成特征向量。 -
构建模型管道: 使用
Pipeline将预处理步骤和决策树分类器组合在一起。 -
划分数据集: 将数据随机划分为训练集和测试集。
-
训练模型: 使用训练数据拟合管道,从而训练决策树模型。
-
预测和评估: 对测试集进行预测,并使用
MulticlassClassificationEvaluator计算准确率。
代码输出
这段代码最后会输出我们的测试集的准确率,这个值表示模型在测试集上的预测准确率。现在运行代码来看看输出的是多少。
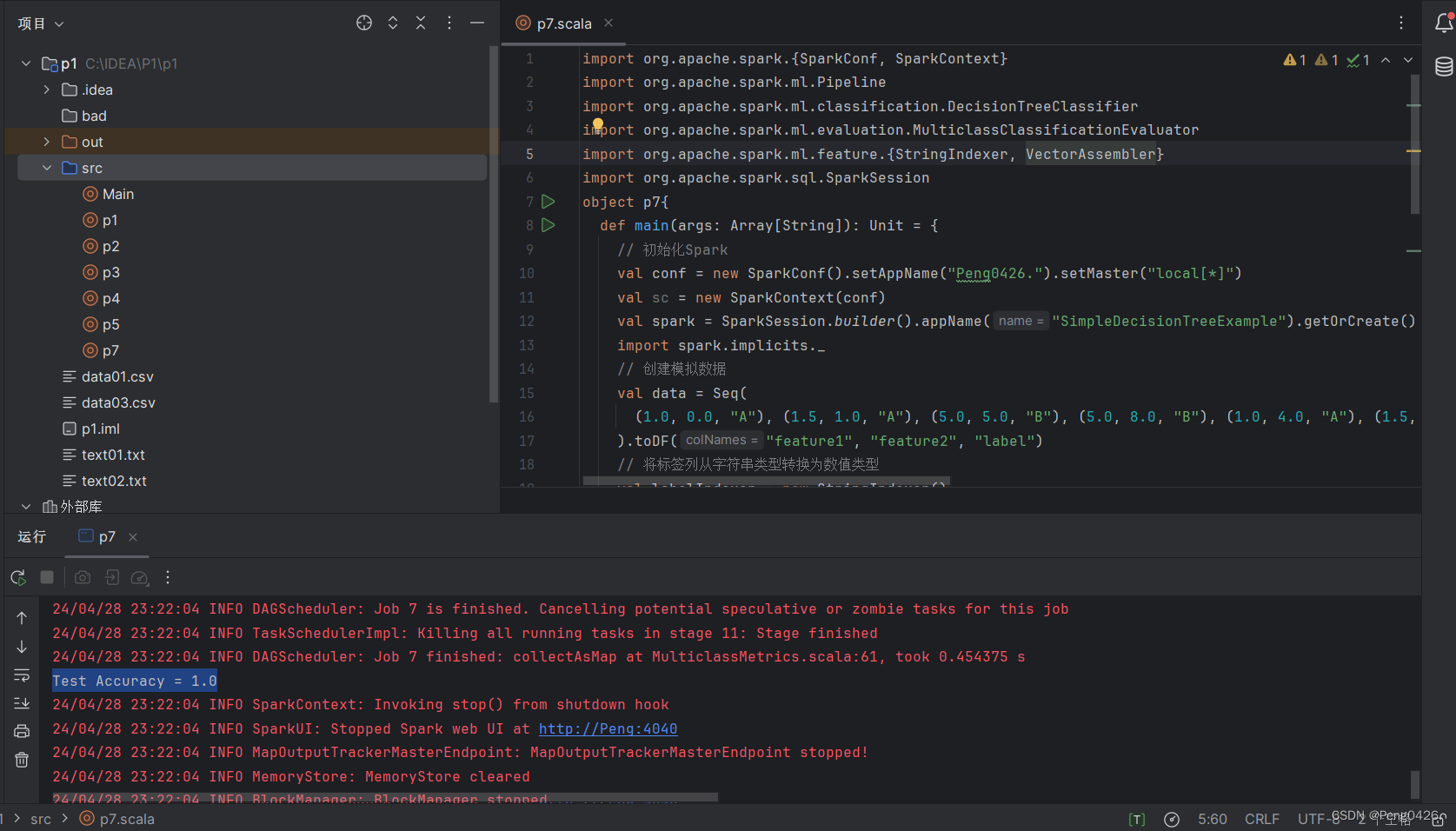 可以看到运行代码后得到了1.0。Accuracy的值只会在0到1之间,越接近1代表我们的模型分类的效果越强,但是我这里的1.0是基于数据集特小,数据不复杂的情况下,在真实的环境中往往很难达到。在实际应用中,我们只需要努力将模型的Accuracy值接近1.0即可。
可以看到运行代码后得到了1.0。Accuracy的值只会在0到1之间,越接近1代表我们的模型分类的效果越强,但是我这里的1.0是基于数据集特小,数据不复杂的情况下,在真实的环境中往往很难达到。在实际应用中,我们只需要努力将模型的Accuracy值接近1.0即可。
拓展-spark决策树
| 关键字 | 描述 | 例子 |
|---|---|---|
| 特征列(featuresCol) | 指定输入数据中的特征列名 | featuresCol="features" |
| 标签列(labelCol) | 指定输入数据中的标签列名 | labelCol="label" |
| 不纯度度量(impurity) | 选择不纯度度量方式,如基尼不纯度或熵 | impurity="gini" |
| 最大深度(maxDepth) | 设置决策树的最大深度 | maxDepth=5 |
| 最小信息增益(minInfoGain) | 设置分裂节点时所需的最小信息增益 | minInfoGain=0.01 |
| 最小实例数(minInstancesPerNode) | 设置分裂后每个节点至少包含的实例数量 | minInstancesPerNode=2 |
| 预测列(predictionCol) | 指定输出数据中的预测结果列名 | predictionCol="prediction" |
| 概率列(probabilityCol) | 指定输出数据中的类别概率预测结果列名 | probabilityCol="probability" |
| 阈值(thresholds) | 用于多分类问题的阈值设置 | thresholds=[0.3, 0.7] |
| 示例数据集 | 使用iris数据集进行分类任务 | 加载iris数据集,设置上述参数进行训练 |


![[论文笔记]GAUSSIAN ERROR LINEAR UNITS (GELUS)](https://img-blog.csdnimg.cn/img_convert/28b6e6ca0e2cbdf1bdbbd7cb2fd3e3f5.png)